

1Kuinの型とリテラル
Kuinの型は、値そのものをやりとりする「値型」と、実行中にメモリ領域を確保してその参照をやりとりする「参照型」とに二分されます。
Kuinにおける値型と参照型は表1-1の通りです。
| 型 | 説明 | 分類 | デフォルト値 | リテラルの例 |
|---|---|---|---|---|
| int | 整数型 | 値型 | 0 | 256 |
| float | 浮動小数点型 | 値型 | 0.0 | 3.14159 |
| char | 文字型 | 値型 | '\0' | 'A' |
| bool | 論理型 | 値型 | false | true |
| bit8 bit16 bit32 bit64 |
ビット型 | 値型 | 0b8 0b16 0b32 0b64 |
255b8 |
| [] | 配列 | 参照型 | null | [1, 2, 3] "abc" |
| list<> | リスト | 参照型 | null | |
| stack<> | スタック | 参照型 | null | |
| queue<> | キュー | 参照型 | null | |
| dict<,> | 辞書 | 参照型 | null | |
| func<()> | 関数型 | 参照型 | null | funcName |
| enum | 列挙型 | 値型 | 値が0の要素 | %elementName |
| class | クラス | 参照型 | null |
「リテラル」とは、ソースコード中で値を書いたもののことです。
「デフォルト値」とは、変数を定義して何も代入していないときに格納されている値のことです。
それぞれの型について、以下で詳しく説明します。
2整数型
「int」は整数を扱うための型で、仕様は図2-1の通りです。
- -9,223,372,036,854,775,808~9,223,372,036,854,775,807の整数を扱う、8byteの型。
- 扱える範囲を超えた場合は値がオーバーフローする
設計の理由
C言語のように様々なサイズの整数型を用意したとしてもメモリ消費量をそこまで切り詰めたいケースは少ないため、Kuinでは簡潔さのために通常用途の整数型は1種類に絞っています。
intのリテラルは、図2-2の通りです。
- 「0123456789」の数字を1つ以上並べたものは、10進数の整数と解釈され、intのリテラルとなる。
- 「0x」に続いて「0123456789ABCDEF」の数字を1つ以上並べたものは、16進数の整数と解釈される。 小文字は許可されない。
設計の理由
16進数の「ABCDEF」が大文字のみを許可している理由は、小文字アルファベットは指数表記やビット型リテラルなどで使うためです。
3浮動小数点型
「float」は小数を扱うための浮動小数点型で、仕様は図3-1の通りです。
- およそ
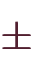
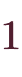

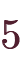


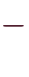


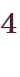 ~
~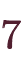

 の、有効桁数15~16桁の浮動小数点数を扱う、8byteの型。
の、有効桁数15~16桁の浮動小数点数を扱う、8byteの型。 - 基本的な仕様はIEEE 754に従う。
- 正および負の無限大を扱うことができ、値がオーバーフローした場合、正もしくは負の無限大になる。
- 値を丸める必要があるとき、0に近いほうに丸められる。
- 「0.0/0.0」など、数学的に未定義な演算を行った場合は結果が「NaN」となる。
- NaNを演算に用いた場合の結果は未定義である。
設計の理由
intと同様、Kuinでは簡潔さのために浮動小数点型は1種類に絞っています。
floatのリテラルは、図3-2の通りです。
- 「0123456789」の数字を2つ以上並べたものの間に「.」が1つだけ含まれていた場合、10進数の小数と解釈され、floatのリテラルとなる。
- この表記に続いて「e+」「e-」があり、その後「0123456789」が続いた場合、指数表記とみなす。
- 「inf」と書くと正の無限大になる。
指数表記とは、「仮数部e+指数部」と書くと「仮数部×10指数部」と見なされる表記方法のことです。 例えば、「1.0e+5」は「10000.0」と同じ値になります。
4文字型
「char」は文字を扱うための型で、仕様は図4-1の通りです。
- 0x0000~0xFFFFのUTF-16の文字コードを扱う、2byteの型。
設計の理由
サロゲートペアの文字を考慮した場合、1文字を4byteとしたUTF-32で扱ったほうが便利になりますが、サロゲートペアの文字を使用する頻度は高くないため、WindowsAPIとの相性が良くメモリ消費量も少ないUTF-16で扱うことにしました。
charのリテラルは、図4-2の通りです。
- 2つの「'」で囲んだ部分は、charのリテラルとなる。
- エスケープシーケンスを使わずにリテラル中に、タブ文字、改行を含めることはできない。
- リテラル中の「\」と任意の1文字との組み合わせは、「エスケープシーケンス」として特殊な文字と解釈される。
「\」と任意の1文字との組み合わせである「エスケープシーケンス」は、全部で表4-1の通りです。
| 記号 | 意味 |
|---|---|
| \\ | 「\」の記号 |
| \" | 「"」の記号 |
| \' | 「'」の記号 |
| \0 | 文字コード0の文字 |
| \n | 改行文字 |
| \t | タブ文字 |
| \u???? | 指定した文字コードの文字。 「????」には数字または大文字アルファベットで4桁の16進数を指定 |
| \{式} | 式の結果を文字列化したもの。 []charリテラル内でのみ使える。 例えば、int型変数nに3が格納されているとき、「"\{n+5}"」と記述すると「"8"」と解釈される。 「(式).toStr()」と等しい |
設計の理由
Windowsでは改行コードは主に、C言語のエスケープシーケンスで「\r\n」(0x0d、0x0a)として表されますが、状況によっては「\r」が不要になったりと煩雑なため、Kuin上では改行は常に「\n」で統一し、内部で適宜「\r\n」に変換を行うようにしています。
5論理型
「bool」は真偽を扱うための論理型で、仕様は図5-1の通りです。
- 「false」か「true」の値を取る、1byteの論理型。
boolのリテラルは、図5-2の通りです。
- 「false」および「true」のみがbool型のリテラルとなる。
- 「false」は偽、「true」は真を表す。
6ビット型
「bit8」「bit16」「bit32」「bit64」はビット演算を行うためのビット型で、仕様は図6-1の通りです。
- 「bit8」は0x00~0xFFの8bit、「bit16」は0x0000~0xFFFFの16bit、「bit32」は0x00000000~0xFFFFFFFFの32bit、「bit64」は0x0000000000000000~0xFFFFFFFFFFFFFFFFの64bitの整数を扱う型。
設計の理由
int型を汎用的に扱える整数型として設計したため、メモリ上の表現を意識しなければならない場合の整数型としてビット型を別に用意しました。
その名の通りビット演算も扱えるので、int型と場面に応じて使い分けると良いでしょう。
ビット型のリテラルは、図6-2の通りです。
- intリテラルの後に「b8」「b16」「b32」「b64」のいずれかを付加したものは、それぞれ「bit8」「bit16」「bit32」「bit64」型のリテラルとなる。
例えば16進数で「AC」の数をbit8型で表現したいときは「0xACb8」とします。
7配列
Kuinの配列は、実行時に要素数を決定できる動的配列で、仕様は図7-1の通りです。
- 配列は「[]型名」と表現する。 例えば「[]int」としたり、配列の配列として「[][]char」のように表現できる。
- Kuinにおける文字列は「[]char」として扱う。
設計の理由
文字列を専用の型ではなくchar型の配列にしている理由は、配列のために用意された各種機能がそのまま利用できるからです。
配列のリテラルは、図7-2の通りです。
- 配列のリテラルは「[値1, 値2, …, 値n]」とする。
- 各値の型は統一されていなければならない。 値の型を元に、配列リテラルの型が決定される。
- 配列リテラルの値をすべてnullにすることは、配列リテラルの型が決定できないため許可されない。 すべてnullにしたい場合は、そのうち1つを明示的にキャストする必要がある。
- 上記に加え、2つの「"」で囲んだ部分は、「[]char」のリテラルとなる。 []charリテラルの表記ルールは、charリテラルと等しい。
8リスト
リストとは配列に似ていますが、要素の追加・挿入・削除が高速なデータ構造です。 リストの仕様は図8-1の通りです。
- リストは、各要素がポインタで連結しているデータ構造で、「list<型名>」と表現する。 例えば「list<int>」などとする。
- 配列と比べて要素の追加・挿入・削除が瞬時に行える反面、n番目の要素にアクセスする処理は遅くなる。
- またリストは双方向に連結しているため、先頭から順に辿るほか、末尾から逆順に辿ることもできる。
9スタック
スタックとは、先に入れた要素が後に取り出される積み荷のようなデータ構造です。 スタックの仕様は図9-1の通りです。
- スタックは「stack<型名>」と表現する。 例えば「stack<int>」などとする。
10キュー
キューとは、先に入れた要素が先に取り出される待ち行列のようなデータ構造です。 キューの仕様は図10-1の通りです。
- キューは「queue<型名>」と表現する。 例えば「queue<int>」などとする。
11辞書
辞書とは、キーと値のペアをいくつも格納するようなデータ構造で、キーから値を高速に探索したいときに使います。 辞書の仕様は図11-1の通りです。
- 辞書は「dict<キーの型名, 値の型名>」と表現する。 例えば「dict<[]char, int>」などとする。
- キーの検索には二分探索を用いるため、配列やリストなどで先頭から順に検索するよりも遥かに高速に処理される。
12関数型
Kuinではすべての関数は関数型として扱われます。 関数を関数型の変数に代入して扱うこともできます。 関数型の仕様は図12-1の通りです。
- 関数型は、関数の型で、「func<(引数1の型, 引数2の型, ..., 引数nの型): 戻り値の型)>」と表現する。 例えば「func<(int, char): bool>」などとする。
- 関数型の値は関数そのものであり、関数呼び出しできる。
13列挙型、クラス
列挙型およびクラスは、ユーザが自由に中身を定義できる型です。